What Is Hadoop & Big Data?
Apache Hadoop was born out of a need to process an avalanche of big data. The web was generating more and more information on a daily basis, and it was becoming very difficult to index over one billion pages of content. In order to cope, Google invented a new style of data processing known as MapReduce. A year after Google published a white paper describing the MapReduce framework, Doug Cutting and Mike Cafarella, inspired by the white paper, created Hadoop to apply these concepts to an open-source software framework to support distribution for the Nutch search engine project. Given the original case, Hadoop was designed with a simple write-once storage infrastructure.
Hadoop has moved far beyond its beginnings in web indexing and is now used in many industries for a huge variety of tasks that all share the common theme of lots of variety, volume and velocity of data – both structured and unstructured. It is now widely used across industries, including finance, media and entertainment, government, healthcare, information services, retail, and other industries with big data requirements but the limitations of the original storage infrastructure remain.
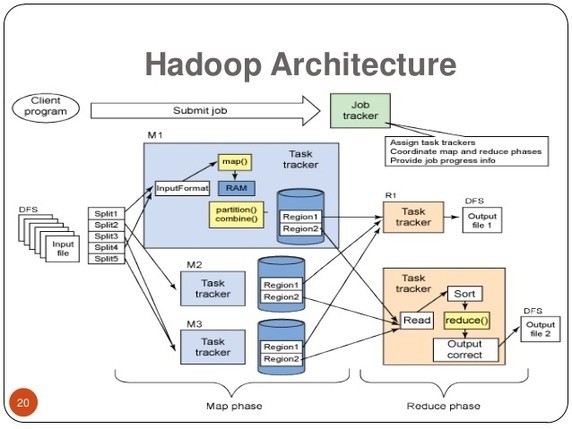
The Big Data Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Benefits of Hadoop & Big Data
Hadoop can handle data in a very fluid way
Hadoop is more than just a faster, cheaper database and analytics tool. Unlike databases, Hadoop doesn’t insist that you structure your data. Data may be unstructured and schemaless. Users can dump their data into the framework without needing to reformat it. By contrast, relational databases require that data be structured and schemas be defined before storing the data.
Hadoop has a simplified programming model
Hadoop’s simplified programming model allows users to quickly write and test software in distributed systems. Performing computation on large volumes of data has been done before, usually in a distributed setting but writing software for distributed systems is notoriously hard. By trading away some programming flexibility, Hadoop makes it much easier to write distributed programs.
Hadoop is easy to administer
Alternative high performance computing (HPC) systems allow programs to run on large collections of computers, but they typically require rigid program configuration and generally require that data be stored on a separate storage area network (SAN) system. Schedulers on HPC clusters require careful administration and since program execution is sensitive to node failure, administration of a Hadoop cluster is much easier.
Hadoop is Agile
Relational databases are good at storing and processing data sets with predefined and rigid data models. For unstructured data, relational databases lack the agility and scalability that is needed. Apache Hadoop makes it possible to cheaply process and analyze huge amounts of both structured and unstructured data together, and to process data without defining all structure ahead of time.
It’s cost effective
Apache Hadoop controls costs by storing data more affordably per terabyte than other platforms. Instead of thousands to tens of thousands per terabyte, Hadoop delivers compute and storage for hundreds of dollars per terabyte.
It’s fault-tolerant
Fault tolerance is one of the most important advantages of using Hadoop. Even if individual nodes experience high rates of failure when running jobs on a large cluster, data is replicated across a cluster so that it can be recovered easily in the face of disk, node or rack failures.
It’s flexible
The flexible way that data is stored in Apache Hadoop is one of its biggest assets – enabling businesses to generate value from data that was previously considered too expensive to be stored and processed in traditional databases. With Hadoop, you can use all types of data, both structured and unstructured, to extract more meaningful business insights from more of your data.
It’s scalable
Hadoop is a highly scalable storage platform, because it can store and distribute very large data sets across clusters of hundreds of inexpensive servers operating in parallel. The problem with traditional relational database management systems (RDBMS) is that they can’t scale to process massive volumes of data.
Our Capabilities : A company's technology organization should support its business strategy, not constrain it. TMV. focuses first on the strategic needs of our clients' businesses to determine the technology capabilities needed to support their long-term goals. We help companies address technology-related decisions and ensure their IT organizations and operating models are agile and effective, equipping them to cut through the noise of fleeting technology trends to create enduring results.
IT Strategy
Technology helps companies transform themselves and grow their business.
Heavily technology-dependent to identify the optimal future state of IT
Aligned with business needs
Jointly develop an implementation blueprint.
Focused Service Provider
Applied best practices for Application Development & Maintenance (AD&M)
Expertise in each area of the Software Development Lifecycle (SDLC)
Excellence in development technologies
Leverage re-usable programming assets
Mature Processes
CMMI-compliant methodologies, perfected over a decade of practice, and specifically designed for geographically distributed (nearshore / offshore / onsite) projects.
Measurable project metrics
High level of internal control and efficiency
Stability
Cultivated long term client relationships
Compound annual growth rate - CAGR: 60% (over past 3 years)
Employee retention rate: 90%
Strong group financial position
Prosperous customer relationships – over 90% client retention rate
Easy to work with
Flexibility – In our engagement models (contractual, pricing, SLA, KPI)
Engineers with experience gathered from projects implemented all over the world
Advanced technological infrastructure and security system for maximum client confidence
